My journey with Splunk Connect for Kafka.
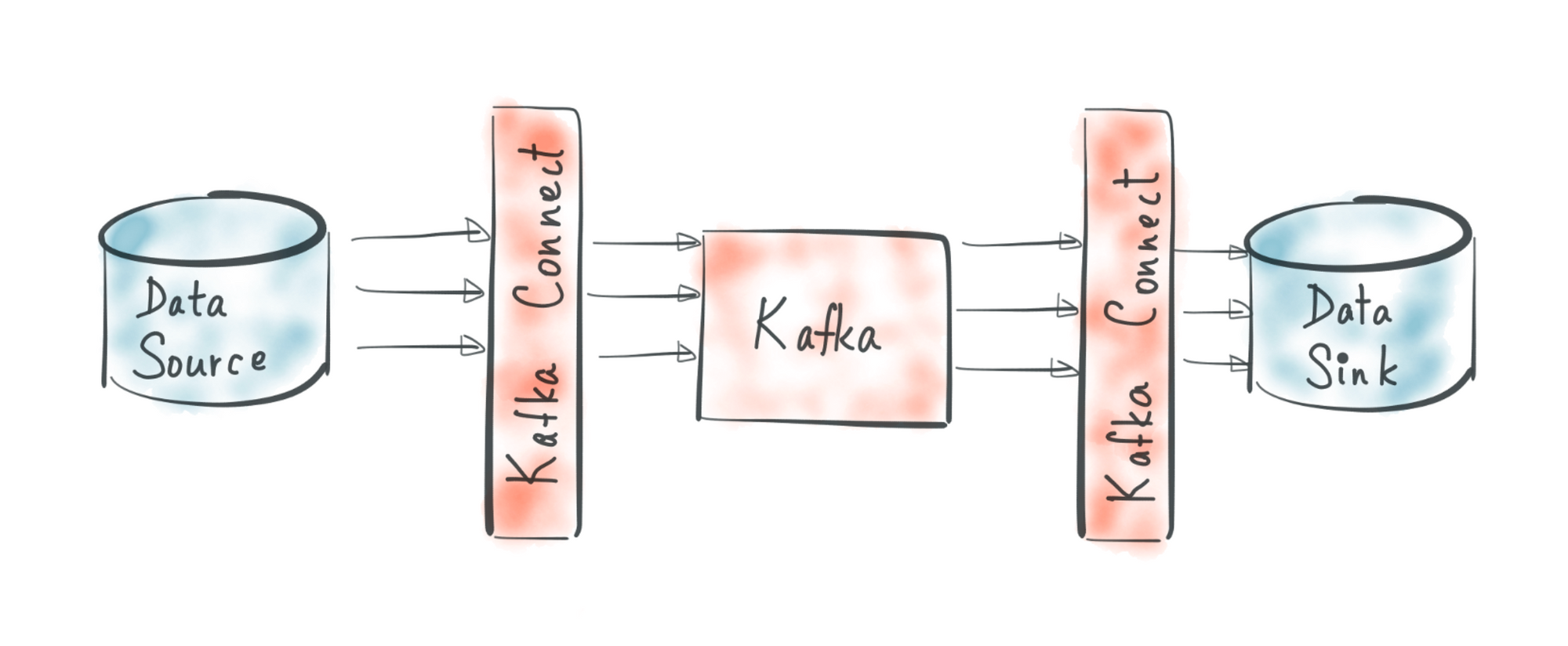
Splunk Connect for Kafka (aka SC4K) allows to collect events from Kafka platform and send them to Splunk. While the sending part (to Splunk) was pretty straight forward to me, the collection part (from Kafka) was very new, as I’ve had no experience with Kafka eco-system. So I guess will start with it.
This will not be a comprehensive guide about Kafka system, how to run massive Kafka clusters nor I will be covering all the possible configuration options for SC4K, but rather I will (hopefully) give you enough information (and jargon) about Kafka Connect to be able to talk to Kafka admins in your organisation and/or, as it was in my case, to run a distributed Splunk Connect for Kafka cluster yourself. As I am learning this myself, some (many) things might be obvious to others, some might be wrong and I will be updating this post as I progress with my journey, so do expect some sections to be empty (or have a “TBC” placeholder)
Kafka and Kafka Connect eco-system
As per the official project site: “Apache Kafka is an open-source distributed event streaming platform“.
Kafka is run as a cluster of one or more servers. Some of these servers form the storage layer, called the brokers. ZooKeeper servers are primarily used to track the status of nodes in the Kafka cluster and maintain a list of Kafka topics and messages. Other servers run Kafka Connect to continuously import and export data as event streams.
When you read or write data from/to Kafka, you do this in the form of events.Events are send to and consumed from topics. Events are organised and durably stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers.

A good explanation about Kafka Connect can be found here
- Connector: is a job that manages and coordinates the tasks. It decides how to split the data-copying work between the tasks.
- Task: is piece of work that provides service to accomplish actual job.
- Worker: is the node that is running the connector and its tasks.
- Transforms: optional in-flight manipulation of messages
- Converters: handling serialization and deserialization of data
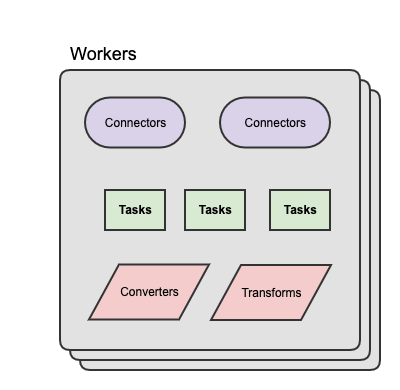
Connectors divide the actual job into smaller pieces as tasks in order to have the ability to scalability and fault tolerance. The state of the tasks is stored in special Kafka topics, and it is configured with offset.storage.topic, config.storage.topic and status.storage.topic . As the task does not keep its state it can be started, stopped and restarted at any time or nodes.
Confusingly, in the documentation, Connector can refer to:
- Connector Worker / Connector Cluster
- Specific Sink/Source Connector binary (jar)
- Instance of a Source/Sink Connector running in a Worker
One more thing, Confluent Platform is a vendor based distribution that includes the latest release of Kafka and additional tools and services that make it easier to build and manage an Event Streaming Platform.
Base Installation
As it was mentioned before, Kafka Connect is part of Kafka system and it is shipped with Kafka binaries. So download it, It’s your/organisational choice whether to go with “plain” Apache Kafka or get the Confluent Community/Enterprise Platform (more info here)
For the sake of simplicity let’s assume “vanilla” Apache Kafka from here
Download the latest SC4K archive from GitHub (you will only need the jar file).
Extract kafka and rename the folder to commit the version
$ tar -xzvf /tmp/kafka_2.13-2.8.0.tgz -C /opt/ $ mv /opt/kafka_2.13-2.8.0/ /opt/kafka/ $ cd /opt/kafka/
Create a plugins directory and copy (the downloaded) SC4K jar into it
mkdir /opt/kafka/plugins/ cp /tmp/splunk-kafka-connect-v2.0.2.jar /opt/kafka/plugins/
That’s it now we have all the binaries and we can start Splunk Connect for Kafka
Starting Kafka
Following will be required if you are starting you own Kafka cluster. If you are using an existing Kafka cluster you can skip it.
Start Zookeeper
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Open a new terminal session and start Kafka Broker
$ bin/kafka-server-start.sh config/server.properties
Simple Worker Configuration
So now we are ready to start a our Kafka Connect. Assuming the most simple configuration, the only thing we will need to know is the Kafka Broker host and port, which, in case we we are using out-of-the-box from previous step, will be locahost:9092
Update your config/connect-distributed.properties
One can start updating properties in the file one by one. Or just copy the content of the file provided in the SC4K GitHub repository.
The “most” important thing is bootstrap.servers, if you are not running Kafka Brokers on the same host change it (from the default localhost:9092) accordingly .
When connecting to an existing cluster you will need to consider a few things about storage topics, encryption, etc
Let’s start the Kafka Connector Worker. Open a new session and run
$ bin/connect-distributed.sh config/connect-distributed.properties
if you want to have more then one Worker in your cluster, just repeat the steps described in this section
You can check the status of you worker by running
curl http://localhost:8083/
All the following configuration (on a connector running in a distributed mode) is done via its REST API, I am using curl here, but one can off course use any other client of his choice, like Postman
Splunk Connect for Kafka Connector Instance Configuration
So, we have a Kafka Connector cluster running, but it is sitting “idle” (just burning our CPU cycles) as it has no defined Connector Instances (I told you that “connector” term is quite ambiguous in Kafka eco-system) .
Lets say you have a topic named web_json where some application is pushing events and you want these to be indexed in web index with sc4k_web_json sourcetype,
You will need to know the URL of Splunk’s HEC endpoint (which I assume you already have running) and a HEC token to use (i.e. already configured on Splunk side).
Now let’s run this REST API call,
Going Above Base
Storage topics
SC4K (or any other Kafka Connector) in distributed mode relies of 3 topics for storing its configuration and progress, These are defined in the config/connect-distributed.properties
config.storage.topic– The name of the Kafka topic where connector configurations are storedoffset.storage.topic– The name of the Kafka topic where connector offsets are storedstatus.storage.topic– The name of the Kafka topic where connector and task status are stored
If you are running the Broker(s) on a local (or other permissive environment), the Connector will create these topics for you with replication factor and number of partitions based on values provided in *.storage.replication.factor and *.storage.partitions respectively.
In a more restricted (read enterprise) environment Kafka cluster administrator might create these for you beforehand. If that is the case, the important thing will be to get the names for each topic that were created in the cluster and update config/connect-distributed.properties file with them, while also removing the *.storage.replication.factor and *.storage.partitions properties
Hardening
Let’s talk a bit about the certificates that are used in SC4K. Of course these will greatly depend on the environment configuration in which you will be running.
Here are the touch points that I had to care about:
- Splunk HEC (server) certificate
- Kafka Broker (server) certificate
- SC4K (client) certificate
Splunk HEC (server) certificate
Splunk’s HEC endpoint was using HTTPs and had a certificate provisioned by the organisation root CA. So in order for SC4K to trust the HEC certificate we need to add the organisation root CA to SC4K’s truststore
Kafka Broker (server) certificate
Same story as with HEC – Broker endpoint is hardened with a certificate signed by organisation’s root CA,
SC4K (client) certificate
In this environment, access to topics was implemented using SSL with client certificates so SC4K had to be configured to use a client certificate to communicate with Kafka Broker.
Schema Registry
Avro Converters
References
- https://kafka.apache.org/
- https://turkogluc.com/apache-kafka-connect-introduction/
- https://github.com/splunk/kafka-connect-splunk
Related posts about Splunk
Add new LLM models to Splunk MLTK
Predicting multiple metrics in Splunk
Splunk Failed to apply rollup policy to index… Summary span… cannot be cron scheduled
How to collect StatsD metrics from rippled server using Splunk
Plotting Splunk with the same metric and dimension names shows NULL
Splunk Eventgen Jinja templating
How to Register to Splunk Partner Portal and transfer Certifications and Learning