I am learning about different concepts and architectures used in the LLM/AI space and one of them is Retrieval-Augmented Generation. As always I prefer learning concepts by tinkering with them and here is my first attempt at learning about RAG and Vector Databases.
A bit of the terminology,
I will not dive too deep here, but just enough to get started. The definitions below are my simplified understanding, and they are most likely not fully correct.
What is RAG
There are many places where you can learn about RAG, but for the context of this post, I’d say that RAG allows you to supplement the initial prompt for the LLM with a bit more (or a lot more, that’s up to you) context.
What is a Vector Database?
Vector Database is one of the mechanisms/data stores that will enable you to provide this additional context to the LLM. Unline “regular” databases, vector database doesn’t necessarily store the actual data (though it can), but it will store the embedding of the data you later wish to search to retrieve the above-mentioned context.
What are embeddings?
Embeddings are multi-dimensional numerical representations of a piece of data (text for example), The multi-dimensionality allows to “place” semantically similar terms close to each other. For example, if using semantic search we search for “dog” then “puppy” and “mutt” and mutt will be considered close terms, while if using a lexical search (one that looks at the literal text similarity), will probably consider “dogma” and “hot dog” as closer terms.
The ITSM Assistant
The problem
Now let’s say you want to open a ticket in your ITSM ticketing system that your Internet Access is not working properly. You could start by searching for a particular request type or a knowledge base article, but what if you are not a technically savvy person and all you care about is that you can’t get to Facebook?
The Solution
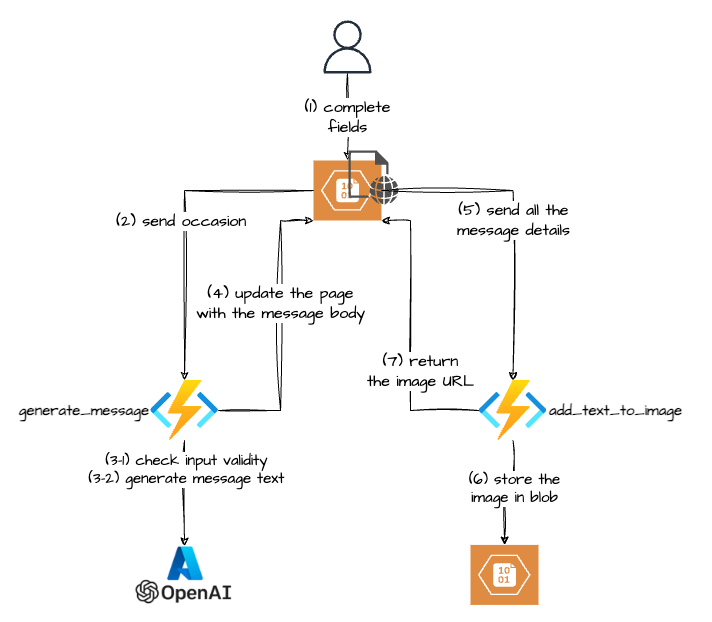
ITSM Assistant to the rescue!!! It’s a chat interface that will:
- ask a user about the issue they are currently facing
- will look in the vector database for semantically similar historical requests, and get their IDs
- get the content of the tickets from the data store (simple CSV file int in this case)
- will feed this context to an LLM
- provide a user with the suggested request form and some of the fields that should be populated
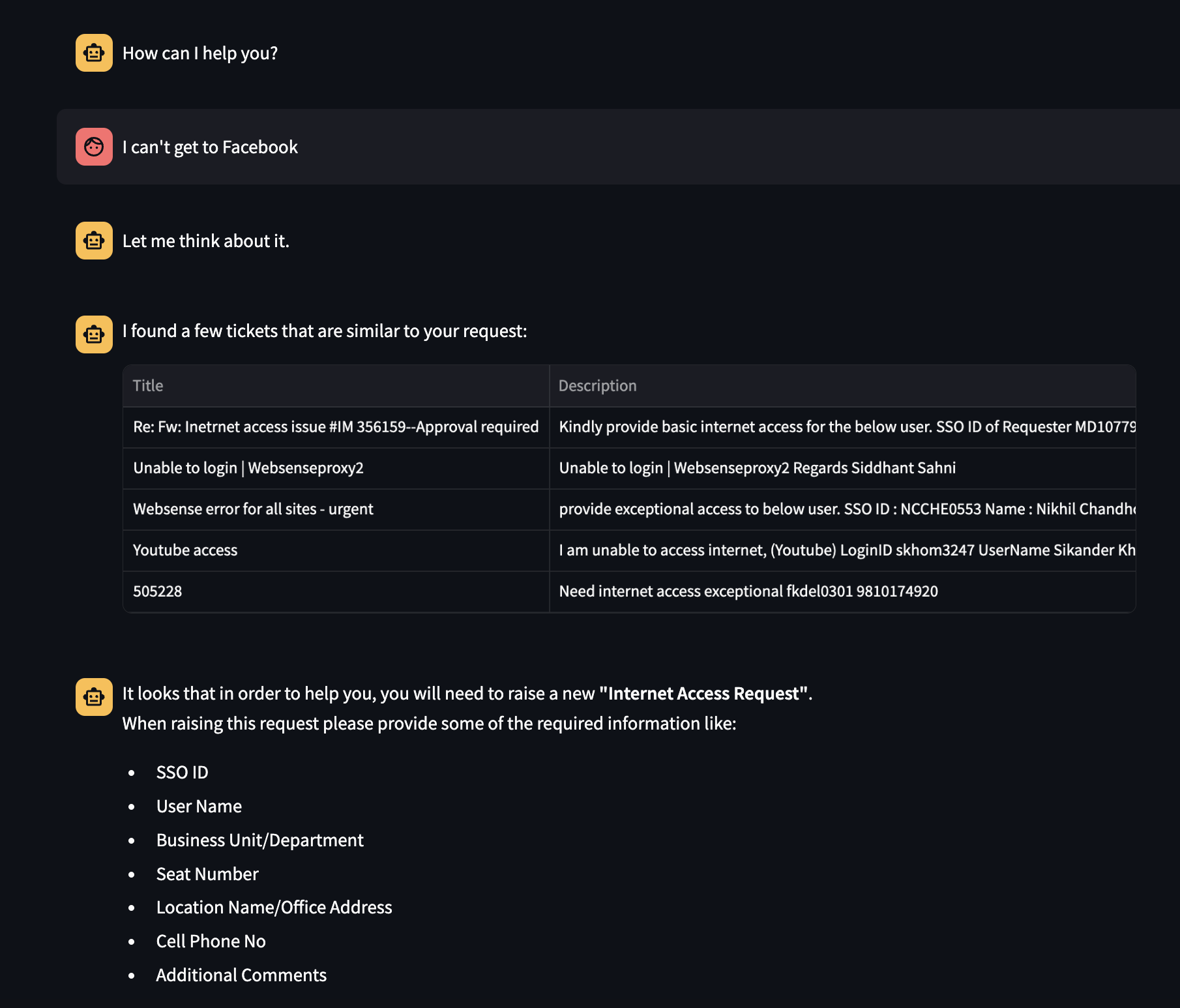
As you can see in the screenshot below the user didn’t mention that they have problems with “internet access”, but just said, “I can’t get to Facebook”. Despite that ITSM Assistant was able to pull data that is related semantically to the user’s issue. LLM (after being fed all the context) suggested the correct Service Request type and some of the information the user should add to the ticket for it to be promptly resolved.
How it works under the hood?
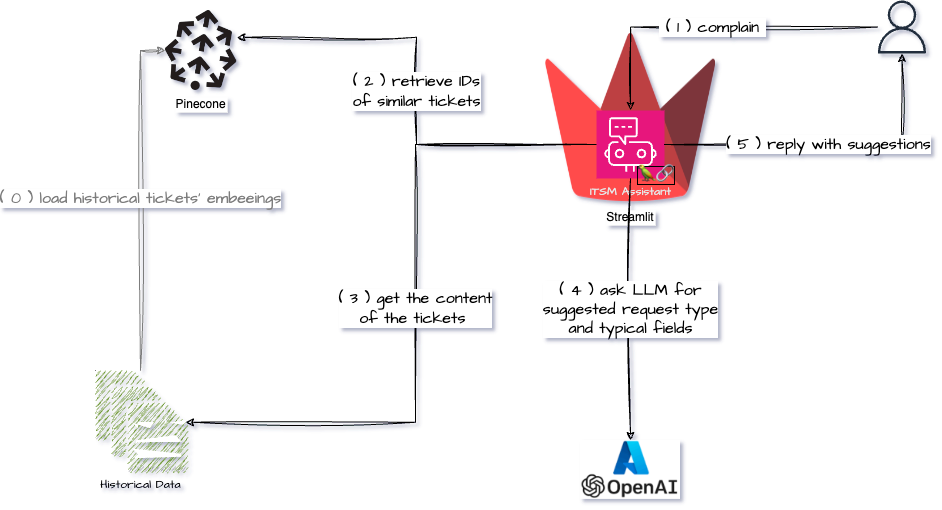
The components
- Pinecone – vector database
- Streamlit – “…turns data scripts into shareable web apps in minutes.”, both front and back-end all in Python.
- Stramlit Community Cloud – for hosting the Stremalit app
- AzureOpenAI – the LLM
- all-MiniLM-L6-v2 – “…a sentence-transformers model: It maps sentences & paragraphs to a 384-dimensional dense vector space”
Step 0 – Load the data into Vector Database
I found an ITSM ticket dump on the internet.
Next, we need to get embedding for each ticket and insert it into the vector database (Pinecone in my case).
I had a Jupiter notebook that was doing this job.
# Importing the necessary libraries
import pandas as pd
# Importing the csv file
data = pd.read_csv('GMSCRFDump.csv', encoding = 'ISO-8859-1')
# removing duplicate tickets
ID_mins = data.groupby(['Title', 'Description', "CallClosure Description"]).ID.transform("min")
data_n = data.loc[data.ID == ID_mins]
# create a new array with a field that has both title and description each ticket
title_description = data_n['Title'] + " __ " + data_n['Description']
# create an arraid of ticket IDs
tid = data_n['ID']
# import a transformer that will be used to encode the ticket data
from sentence_transformers import SentenceTransformer
import torch
# Define the model
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = SentenceTransformer('all-MiniLM-L6-v2', device=device)
# Setup Pinecone connection
import os
os.environ['PINECONE_API_KEY'] = '1b5da094-f784-4beb-8fc3-262712a667ae'
os.environ['PINECONE_ENVIRONMENT'] = 'gcp-starter'
from pinecone import Pinecone, PodSpec
# get api key from app.pinecone.io
api_key = os.environ.get('PINECONE_API_KEY') or 'PINECONE_API_KEY'
# find your environment next to the api key in pinecone console
env = os.environ.get('PINECONE_ENVIRONMENT') or 'PINECONE_ENVIRONMENT'
pinecone = Pinecone(api_key=api_key)
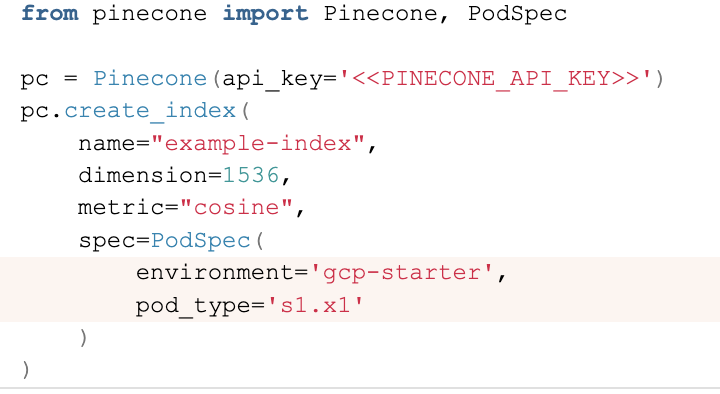
# Create index
index_name = 'snow-data'
# only create index if it doesn't exist
if index_name not in pinecone.list_indexes().names():
pinecone.create_index(
name=index_name,
dimension=model.get_sentence_embedding_dimension(),
metric='cosine',
spec=PodSpec(
environment=env,
pod_type='s1.x1'
)
)
# now connect to the index
index = pinecone.Index(index_name)
# the following section, takes a batch of tickets, for each one of them makes and embeeding, "attaches" id and title+description as meta data , and upserts that into Pinecone index
from tqdm.auto import tqdm
batch_size = 120
vector_limit = 12000
title_description = title_description[:vector_limit]
title_description
for i in tqdm(range(0, len(title_description), batch_size)):
# find end of batch
i_end = min(i+batch_size, len(title_description))
# create IDs batch
ids = [str(x) for x in range(i, i_end)]
# create metadata batch
metadatas = [{'tid': t_id, 'text': t_desc} for t_id, t_desc in list(zip(tid,title_description))[i:i_end]]
print(metadatas)
# create embeddings
xc = model.encode([t_desc for t_desc in title_description[i:i_end]])
# create records list for upsert
records = zip(ids, xc, metadatas)
# upsert to Pinecone
index.upsert(vectors=records)
Step 1 – The Streamlit App
Streamlist is a straightforward Python framework that allows you to build (simple) web apps. All without any HTML, JavaScript and CSS knowledge. You can run it locally or host it somewhere, for example using their Community Cloud.
You can find the code for the app in the ITSM Assistant repo here. So I’ll not provide much code from now on, but instead, talk to write about my any caveats.
To try it at home one will need to create secrets.toml file under the .streamlit folder and populate it with your Azure OpenAI and Pinecone credentials/configuration
AZURE_OPENAI_API_KEY = "xxxxxxxxxxxxx" AZURE_OPENAI_ENDPOINT = "https://xxxxxxxxx.openai.azure.com/" PINECONE_API_KEY = "xxx-xxx-xxx-xx" PINECONE_INDEX = "snow-data"
Steps 2 and 3 – Searching for Historical Tickets
One caveat is depending on the amount of data one can decide to upsert into the vector db (in addition to the embeddings themselves) not only ticket ID (as metadata), but all the ticket fields (like Description, Resolution, etc.). This way your semantic search can return all the data you need and there is no need to have Step 4 (retrieval of data from data store)
For the sake of learning, I did not, so after we get ticket IDs from Pinecone, we use it to filter the data in the data store (fancy name for CSV) to get the ticket information that needs to be sent as context to the LLM.
Step 4 – Ask LLM for help
Now that we have the context (similar ticket data) we can send the request to LLM to help our struggling user and point them in the right direction.
Step 5 – Response to User
The only thing worth mentioning here is I had a bit of a struggle in printing the list of fields nicely.
LLM is coming back with a JSON response similar to below:
{
"common_theme": "Server Reboot",
"title": "Server Reboot Request",
"suggested_fields": "SSO ID, Name, Email, Seat Number, Location, Cell Phone No"
}
Streamlit can use markdown for output, so to format the list of fields nicely I had to do something like this:
suggested_fields = llm_response['suggested_fields'].split(', ')
suggested_fields = "- " + "\n- ".join(suggested_fields)
nl = " \n"
st.chat_message("ai").markdown(f"It looks that in order to help you, you will need to raise a new **\"{llm_response['title']}\"**.{nl}\
When raising this request please provide some of the required information like:{nl}{suggested_fields}")
P.S.
You can find the app here: https://app-itsm-assistant.streamlit.app/